Exploring the code security space as a strategic focus for Sourcegraph
Organization
Sourcegraph
Role
Staff Product Designer
Date
2022
Sourcegraph is a universal code search and intelligence platform. More than 800,000 developers in some of the largest companies around the world rely on Sourcegraph to search across and navigate all of their company’s code on all of their code hosts.
In early 2022, I joined a small group of engineers and product managers at Sourcegraph on what we called the “Code Security Tiger Team.”
This tiger team and effort was triggered by an ongoing theme we were hearing from customers around code security as a primary use case for Sourcegraph. But, Sourcegraph doesn’t explicitly have a “code security” feature built around code security; instead, the code search product itself is inherently valuable to security team members in their existing workflows. This means that while the value is there for code security, the value is less obvious in sales conversations with engineering leaders.
The team’s mandate was to learn about and explore the problems that security leaders desperately feel, identify opportunities, and make a recommendation whether or not to pursue one of these opportunities.
Ultimately, the team identified a very compelling opportunity space, and at the same time, recommended that we don’t pursue it right now—because it represented too many stacked moonshots.
This was ultimately a fascinating effort that gave me the chance to explore a highly technical problem space, and had the unusual—but correct—outcome of not taking action.
Discovering opportunities
As we kicked off the team’s effort, I led the team in defining a research plan, which we distributed among our group to carry out in parallel.
Along with competitor and industry analysis, we held sessions with security engineers and internal experts. Remarkably, developer experience leaders at several of our customers shared compelling artifacts around problems they are looking to solve around the software supply chain and dependency graph—some of which they were actively looking for solutions, or even trying to build in-house solutions for—but would prefer not to.
Those problems were not solely security-related: they supported both the security and the developer experience workflow, which is a natural evolution of Sourcegraph’s positioning as a universal code search and intelligence platform. In this context, though, security team leaders were stakeholders of the problem.
We soon identified what seemed to be a promising problem space around the supply chain and the dependency graph.
Top problems included:
- When a new security vulnerability arises, leaders want to be able to answer a specific question in relation to time: “Were we exposed to this? When?” in addition to “Are we exposed to this?”
- When a new security vulnerability arises, there is a high cost of “stop the world and fix everything.”
- Knowing a vulnerability exists isn’t the same as knowing that you’re actually exposed to it.
- For leaders, it feels like knowing and seeing the risk profile and implications and using that to inform decisions is more important than quickly fixing things.
- In companies with lots of code, repositories, and services depending on each other creates complexity at scale. A quick fix is rarely encapsulated within clean code / team / group boundaries.
- In relation to the software supply chain, SBOM is a “hot term” right now and gets the attention of security leaders. In addition to its connection to an Executive Order, to some extent, SBOM may also be “hot” because it’s a non-technical concept for a technical problem (“bill of materials”). The tangible artifact that is a SBOM is much less important than the role that an SBOM plays in confidence, traceability, and compliance.
- Leaders care about a different “fidelity” of risk than ICs / teams. While ICs are focused on individual vulnerabilities, leaders view risk as a “portfolio” across their technology, and need to understand where to invest time and resources to reduce that risk is the most effective way.
- Companies with lots of code can’t really “ensure” their software supply chain is secure...
- ... And even if they had the perfect tool that could, they wouldn’t trust that it does, and would likely use more tools anyway.
- “Secure” is only a reflection of a point in time. It’s not about being secure in absolute terms, but rather about guaranteeing that you were never exposed to a specific vulnerability, or guaranteeing that you are no longer vulnerable.
- There’s a broad trend towards “shifting left” in security, moving it earlier in the software lifecycle to when code is being written. Companies are already using a number of tools that address the “left” side of the workflow, focused around helping developers and security teams to prevent vulnerabilities from entering their codebase in the first place. However, these proactive tools and workflows serve a different purpose in the security workflow than are required in reactive scenarios like log4j.
After synthesizing these problems in relation to the business context, the hypothesis the team landed on was:
Security teams and leaders want to understand how, when, and if they are exposed to a security vulnerability in a dependency. When remediation is required, they want to find the most optimal patch sequence to resolve it while minimising effort, build time, and disruptions to production.
This means:
- Knowing if and when they are or were vulnerable.
- Knowing the best way to upgrade with minimum side effects.
- Rolling out those upgrades at scale.
This was a challenging problem to solve because knowing a vulnerability exists isn’t the same as knowing that you’re actually exposed to it. Focusing on the dependency graph problem space would help companies and leaders to answer these questions and understand their risk profile, as well as how to best proceed with updating dependencies at scale.
Relative to the other potential problems the company could focus on, we felt this was a valuable problem to solve right now because:
- Sourcegraph is uniquely positioned to build a solution in this space, because of building blocks already in place. Additionally, the concepts and actions around “search” and “querying” are valuable when it comes to dependencies.
- Sourcegraph is the only tool that our customers use that has all of their code in a single pane of glass.
- N+1 customers were actively assessing and building a solution in this space, with sponsorship from their DevX teams. The investment sounds large in terms of engineering resources, further validating the opportunity.
- It fits into a hot market trend (supply chain security) that will help us with marketing / the sales motion.
- It fits into a workflow within the broader security workflow that is under-addressed: once you find a vulnerability, what do you do? How do you resolve without too much disruption to the business?
- We heard many smaller challenges (e.g. that a security engineer needs to be able to say three months later why they made the call that they were not at risk of a vulnerability) that fit within the general problem space.
- It suggests a larger product opportunity that can be positioned in-product specifically around code security. This will make it easier for folks to quickly understand how Sourcegraph can support the security use case, without having to connect the dots in otherwise separate product features.
- In addition, it suggests a product feature that in itself can grow over time to support further use cases based on ongoing learning and discovery.
Design and exploration
With a clear hypothesis and set of problems, I led the team in going wide to explore the solution space. There were many possible approaches we could take, each with a different set of constraints around implementation, complexity, and how the solution was presented and accessed in the product.
Exploring these approaches involved a lot of collaborative thinking made tangible: story and problem mapping, sketchy interface flows, rapid prototypes, and more.

As we further converged the dependency graph, some approaches that we considered included:
- Creating a separate feature area for code security.
- Adding dependencies to the search query language and surfacing dependencies as a search result type that can be explored.
- Visual dependency graphs that can be shown alongside search results.
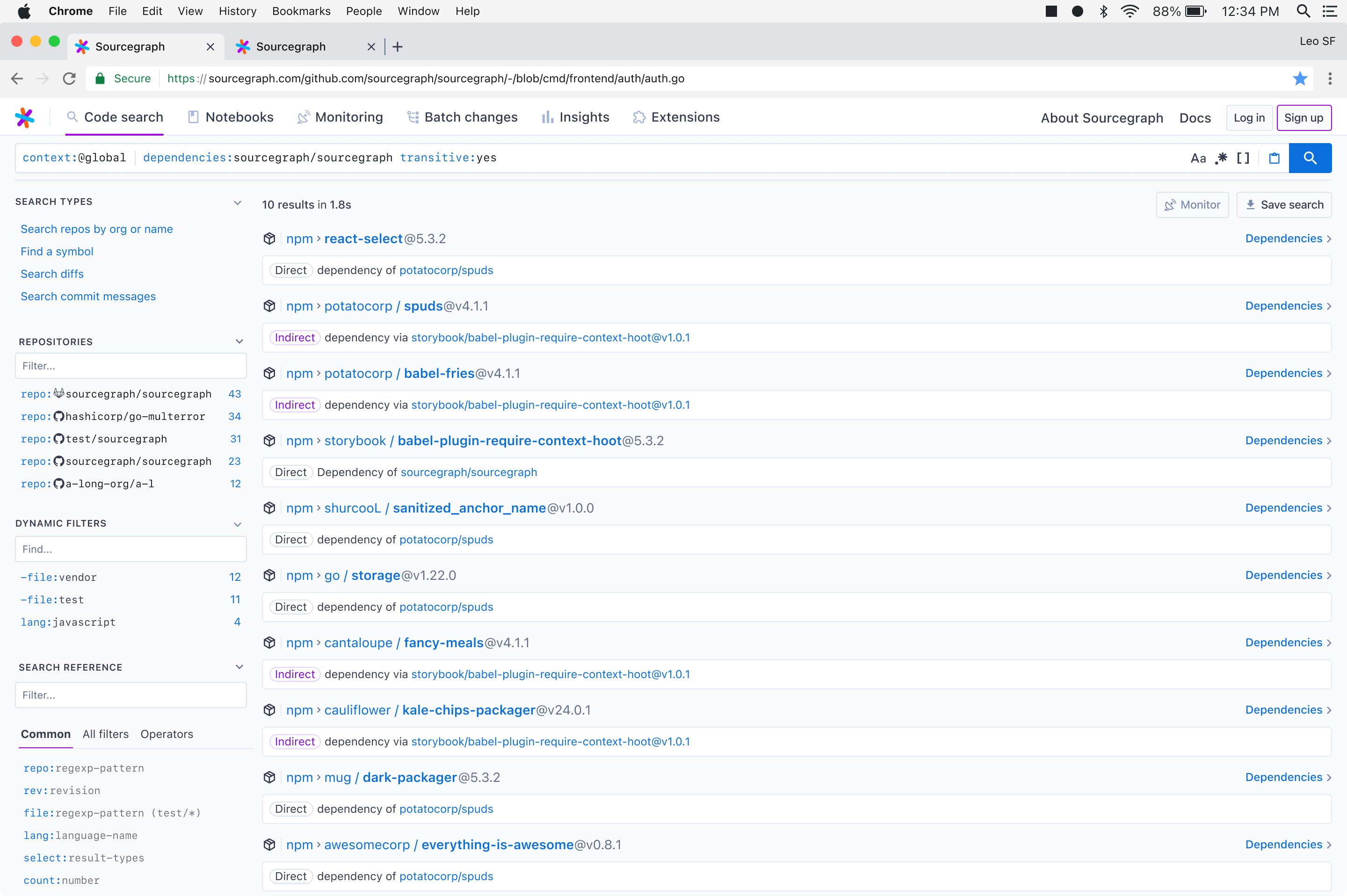
Stacked moonshots
The further we explored the problem and solution space, the more the team began to feel that the timing was not right for the company to invest in this problem space—because it represented stacked moonshots.
An analogy I used to frame these discussions is “roofshots and moonshots.” Most innovative projects need a good moonshot: one big, difficult, audacious thing that will be hard to achieve, but if we do, represents a huge opportunity. However, any given moonshot ought be achievable through a series of roofshots—lower and meaningful iterations that will eventually get us to the moon. This isn’t quite the same as a minimum lovable product, but it’s in the same universe.
The further we went into the solution space, the more we realized that the dependency graph problem space, rather than one moonshot and several roofshots, relied on several moonshots in a row. And, we didn’t ourselves have control over each of moonshots. This massively increases both the risk of failure, and the investment cost in effort and time.
The challenges, as we saw them
- The application of the dependency graph for code security is mostly reactive—when something’s wrong, security folks need to go in and find out if there’s exposure.
- To be trustworthy in a security event, the dependency graph must be complete. We can only do this if customers have precise code intelligence configured. But, adoption of precise code intelligence is historically low due to costs, effort, and maintenance. There’s a dedicated team at Sourcegraph focused on code intelligence, and this team hasn’t yet solved this challenge. Security engineers are dependent user personas on the administrators that set up and manage a Sourcegraph instance, and as such, are not the ones who would be able to own implementing precise code intelligence on their Sourcegraph instance.
- To be useful in a security incident, security engineers already be onboarded to Sourcegraph and have a high level of confidence in the tool that would make them reach for Sourcegraph when a security incident occurs. They will not be open to learning new things in these moments of high stress and rapid decision-making. Sourcegraph's search was previously useful to security engineers in log4j and other events, because these engineers had previously used Sourcegraph for non-urgent activities, and were familiar with what the tool could do and how to use it.
- On the technical side, we would have to invest significant effort (6+ months) into building something that isn't itself validated, in order to validate something else.
None of these are, in isolation, blockers to a successful product solution: but in combination and in relation to the overall business strategy and context and the tiger team’s goals, they represent a level of investment and risk that did not make sense for the company in that moment of time. I, together with the rest of the team, put together this case and shared it with the senior leadership, ultimately reaching consensus that it was not the right time to pursue this effort.
The outcomes of the effort were valuable to us as a business on an ongoing basis: we had a deeper understanding of a key use case, a clear sense of where we could iteratively improve the product over time and how those improvements would have a multiplying impact, and eventually we do intend to return to the space.